YouTube Video Category Classification¶
Pada notebook ini, kita akan mulai untuk membuat model machine learning yang akan mengklasifikasikan kategori video YouTube berdasarkan judul dan deskripsi video. Data yang akan digunakan adalah data video trending YouTube Indonesia.
Tip
Setelah selesai mengunduh, sangat disarankan untuk diletakkan dalam folder data yang sejajar dengan notebook ini.
|- modelling.ipynb
|- data
|- youtube
|- trending.csv
|- category.json
Import Libraries¶
Pertama, kita akan import beberapa library yang akan digunakan pada notebook ini.
from textwrap import wrap
import emoji
import joblib
import langdetect
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import warnings
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
from sklearn.svm import LinearSVC
from sklearn.tree import DecisionTreeClassifier
plt.style.use("fivethirtyeight")
warnings.filterwarnings("ignore")
/Users/bitlabsinstructor/.pyenv/versions/3.8.11/envs/bitlabs-webinar/lib/python3.8/site-packages/pandas/compat/__init__.py:124: UserWarning: Could not import the lzma module. Your installed Python is incomplete. Attempting to use lzma compression will result in a RuntimeError.
warnings.warn(msg)
Data Loading¶
Untuk trending.csv, kita bisa langsung membaca data tersebut menggunakan pandas. Khusus untuk category.json, kita akan definisikan fungsi berikut untuk membantu kita membaca data kategori video.
def get_category_dict(category_file):
category = pd.read_json(category_file, orient="records")
category = pd.DataFrame(category["items"].values.tolist())
return {
cat.id: cat.snippet.get("title")
for cat in category.itertuples(index=False)
}
Note
Karena alasan teknis, kita hanya akan menggunakan data video trending dari bulan Juli sampai Desember saja.
def get_category_dict(category_file):
category = pd.read_json(category_file, orient="records")
category = pd.DataFrame(category["items"].values.tolist())
return {
cat.id: cat.snippet.get("title")
for cat in category.itertuples(index=False)
}
category_dict = get_category_dict("data/category.json")
trending = pd.read_csv("./data/trending.csv", parse_dates=["publish_time", "trending_time"])
with pd.option_context("display.max_columns", None):
display(trending.head())
| publish_time | channel_id | title | description | thumbnail_url | thumbnail_width | thumbnail_height | channel_name | tags | category_id | live_status | local_title | local_description | duration | dimension | definition | caption | license_status | allowed_region | blocked_region | view | like | dislike | favorite | comment | trending_time | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2021-02-05 09:00:34+00:00 | UCEf_Bc-KVd7onSeifS3py9g | aespa 에스파 'Forever (약속)' MV | aespa's new single "Forever" is out!\nListen a... | NaN | NaN | NaN | SMTOWN | NaN | 10 | none | aespa 에스파 'Forever (약속)' MV | aespa's new single "Forever" is out!\nListen a... | PT5M7S | 2d | hd | True | True | NaN | NaN | 7806846.0 | 857902.0 | 24078.0 | 0 | 94961.0 | 2021-02-07 05:46:51.832614+00:00 |
| 1 | 2021-02-04 15:54:08+00:00 | UCYEa4_MC7OFjcWrO6SO-u8g | [FULL] Siapa di Balik Kudeta AHY? | Dua Sisi t... | Jakarta, https://www.tvonenews.com - Ketua umu... | NaN | NaN | NaN | Indonesia Lawyers Club | ['tvone', 'tv one', 'tvonenews', 'indonesia la... | 25 | none | [FULL] Siapa di Balik Kudeta AHY? | Dua Sisi t... | Jakarta, https://www.tvonenews.com - Ketua umu... | PT42M30S | 2d | hd | False | True | NaN | NaN | 885038.0 | 6765.0 | 1263.0 | 0 | 6365.0 | 2021-02-07 05:46:51.832649+00:00 |
| 2 | 2021-02-06 03:00:22+00:00 | UCu12RxQjRQyh79YBYvEDkOg | CABRIOLET CHALLENGE: TANTANGAN MENGGODA (7/12) | Road Party Season 2: Cabriolet Challenge\n\nEp... | NaN | NaN | NaN | Motomobi | ['MotoMobi', 'Mobil', 'motor', 'review', 'indo... | 2 | none | CABRIOLET CHALLENGE: TANTANGAN MENGGODA (7/12) | Road Party Season 2: Cabriolet Challenge\n\nEp... | PT46M43S | 2d | hd | False | True | NaN | NaN | 889708.0 | 47895.0 | 532.0 | 0 | 8785.0 | 2021-02-07 05:46:51.832664+00:00 |
| 3 | 2021-02-05 20:26:08+00:00 | UCCuzDCoI3EUOo_nhCj4noSw | With Windah Basudara & Hans | Join this channel to get access to perks:\nhtt... | NaN | NaN | NaN | yb | NaN | 20 | none | With Windah Basudara & Hans | Join this channel to get access to perks:\nhtt... | PT45M59S | 2d | hd | False | True | NaN | NaN | 1006854.0 | 91973.0 | 3967.0 | 0 | 12957.0 | 2021-02-07 05:46:51.832678+00:00 |
| 4 | 2021-02-03 23:14:54+00:00 | UC14UlmYlSNiQCBe9Eookf_A | 🤯 LATE COMEBACK DRAMA! | HIGHLIGHTS | Granada ... | With just two minutes to play, Barça looked to... | NaN | NaN | NaN | FC Barcelona | ['FC Barcelona', 'برشلونة،', 'Fútbol', 'FUTBOL... | 17 | none | 🤯 LATE COMEBACK DRAMA! | HIGHLIGHTS | Granada ... | With just two minutes to play, Barça looked to... | PT5M12S | 2d | hd | False | True | NaN | NaN | 6275035.0 | 218131.0 | 4289.0 | 0 | 12799.0 | 2021-02-07 05:46:51.832730+00:00 |
start_date = trending.trending_time.min()
end_date = trending.trending_time.max()
print(f"{start_date = }")
print(f"{end_date = }")
start_date = Timestamp('2021-02-07 05:46:51.832614+0000', tz='UTC')
end_date = Timestamp('2021-12-06 06:01:25.828896+0000', tz='UTC')
Bisa kita lihat bahwa data video trending dimulai dari bulan Februari sampai Desember. Untuk itu, kita akan drop data dari bulan Februai sampai Juni.
filtered_trending = trending[trending.trending_time.dt.month >= 7]
start_date = filtered_trending.trending_time.min()
end_date = filtered_trending.trending_time.max()
print(f"{start_date = }")
print(f"{end_date = }")
start_date = Timestamp('2021-07-01 06:01:25.524449+0000', tz='UTC')
end_date = Timestamp('2021-12-06 06:01:25.828896+0000', tz='UTC')
num_videos = filtered_trending.shape[0]
print(f"{num_videos = }")
num_videos = 31600
Terdapat $31.600$ video yang masuk daftar trending setiap harinya dari bulan Juli sampai Desember. Selanjutnya, kita akan lakukan eksplorasi data terlebih dahulu sebelum mulai membuat model machine learning.
Selanjutnya, mari kita lihat bagaimana distribusi missing value pada masing-masing kolom.
filtered_trending.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 31600 entries, 21322 to 52921
Data columns (total 26 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 publish_time 31600 non-null datetime64[ns, UTC]
1 channel_id 31600 non-null object
2 title 31600 non-null object
3 description 30194 non-null object
4 thumbnail_url 0 non-null float64
5 thumbnail_width 0 non-null float64
6 thumbnail_height 0 non-null float64
7 channel_name 31600 non-null object
8 tags 27542 non-null object
9 category_id 31600 non-null int64
10 live_status 31600 non-null object
11 local_title 31600 non-null object
12 local_description 30194 non-null object
13 duration 31600 non-null object
14 dimension 31600 non-null object
15 definition 31600 non-null object
16 caption 31600 non-null bool
17 license_status 31600 non-null bool
18 allowed_region 944 non-null object
19 blocked_region 1081 non-null object
20 view 31600 non-null float64
21 like 31275 non-null float64
22 dislike 31275 non-null float64
23 favorite 31600 non-null int64
24 comment 31478 non-null float64
25 trending_time 31600 non-null datetime64[ns, UTC]
dtypes: bool(2), datetime64[ns, UTC](2), float64(7), int64(2), object(13)
memory usage: 6.1+ MB
Dari informasi di atas, ada beberapa video yang kolom deskripsinya kosong. Untuk alasan modeling nanti, kita akan hapus video yang tidak memiliki teks deskripsi.
filtered_trending.dropna(subset=["description"], inplace=True)
Exploratory Data Analysis¶
Pertama, karena setiap hari, bahkan setiap beberapa jam, daftar trending di YouTube selalu ada pembaruan, mari kita lihat jumlah video dari hari per hari. Langkah-langkahnya yaitu:
Kelompokkan data berdasarkan tanggal per hari
Hitung jumlah video pada tanggal tersebut
trending_by_date = filtered_trending.groupby(
filtered_trending.trending_time.dt.date
)
num_trending_per_day = trending_by_date.trending_time.count()
print("Number of videos in trending per day:", num_trending_per_day.unique())
Number of videos in trending per day: [195 196 197 198 194 193 192 191 190 188 187 185 189 186 184 183]
Jadi, setiap harinya, terdapat 200 video yang masuk dalam daftar trending YouTube dari tanggal 1 Juli sampai 6 Desember.
Trending Duration¶
Video masuk trending YouTube kadang kala juga bisa bertahan beberapa hari. Lama bertahannya video dalam daftar trending ini mungkin disebabkan oleh beberapa faktor seperti jumlah like, jumlah view, kecepatan kenaikan kedua metrik tersebut, dan lainnya. Mari kita lihat berapa lama durasi suatu video bertahan dalam trending YouTube.
trending_duration = filtered_trending.groupby("title").agg(
trending_duration=pd.NamedAgg(column="trending_time", aggfunc="count"),
trending_start_date=pd.NamedAgg(column="trending_time", aggfunc="min"),
trending_last_date=pd.NamedAgg(column="trending_time", aggfunc="max")
).sort_values("trending_duration", ascending=False).reset_index()
trending_duration.head(10)
| title | trending_duration | trending_start_date | trending_last_date | |
|---|---|---|---|---|
| 0 | Måneskin - Beggin' (Lyrics/Testo) | 30 | 2021-07-06 06:01:08.609842+00:00 | 2021-08-14 06:01:09.572758+00:00 |
| 1 | Måneskin - Beggin' (Lyrics) | 30 | 2021-07-09 06:03:40.293908+00:00 | 2021-09-29 06:00:48.508222+00:00 |
| 2 | The Kid LAROI, Justin Bieber - Stay (Lyrics) | 22 | 2021-08-07 06:00:58.727254+00:00 | 2021-11-02 06:00:52.042819+00:00 |
| 3 | Happy Asmara - Lemah Teles (Official Music Liv... | 21 | 2021-07-19 06:02:49.428626+00:00 | 2021-08-08 06:01:02.782146+00:00 |
| 4 | WONDERLAND INDONESIA by Alffy Rev (ft. Novia B... | 21 | 2021-08-18 06:00:55.039010+00:00 | 2021-09-07 06:00:48.332429+00:00 |
| 5 | DENNY CAKNAN FT. NDARBOY GENK - MENDUNG TANPO ... | 20 | 2021-07-28 06:00:52.529306+00:00 | 2021-08-16 06:01:24.371425+00:00 |
| 6 | Join the BTS #PermissiontoDance Challenge only... | 20 | 2021-08-07 06:00:58.726624+00:00 | 2021-08-26 06:00:52.511071+00:00 |
| 7 | MERINDING GUE DENGER INI, GOKIL‼️ SEREM ABIS‼️... | 20 | 2021-07-02 06:01:02.071087+00:00 | 2021-07-21 06:01:23.252876+00:00 |
| 8 | Create your own short to Shivers using #Sheera... | 20 | 2021-10-26 06:00:53.187313+00:00 | 2021-11-14 06:01:05.587878+00:00 |
| 9 | BTS (방탄소년단) 'Permission to Dance' Official MV | 20 | 2021-07-10 06:01:04.439918+00:00 | 2021-07-29 06:00:56.665583+00:00 |
plt.figure(figsize=(15, 6))
plt.bar(
trending_duration.title[:10].apply(lambda title: "\n".join(wrap(title, width=10))),
trending_duration.trending_duration[:10]
)
plt.title("Longest Duration of Videos included in YouTube Trending Video", loc="left")
plt.xlabel("Video Title")
plt.ylabel("Trending Duration (in days)")
plt.grid(False)
plt.show()
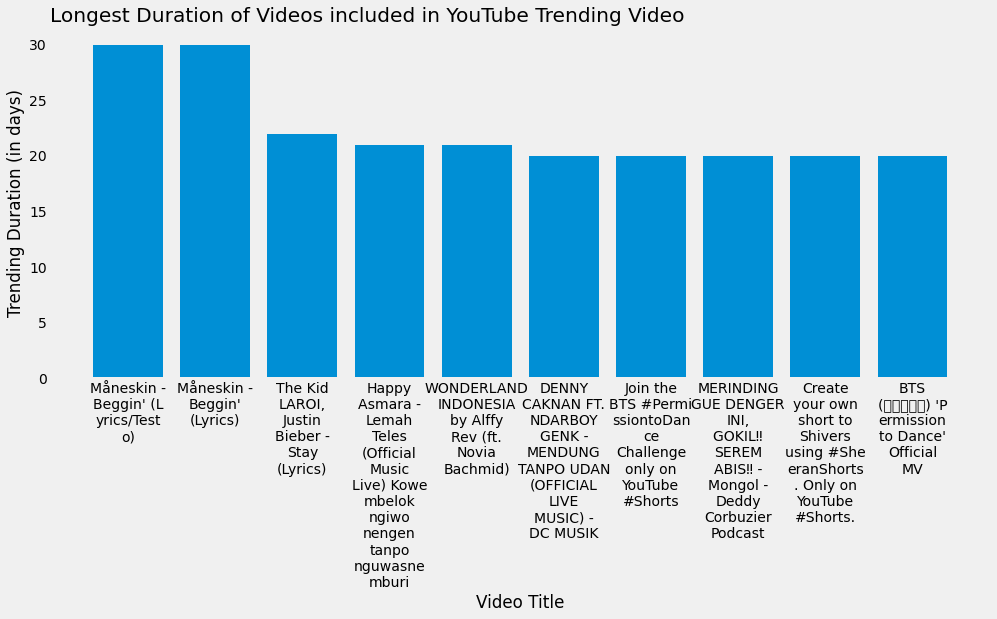
Tip
Silakan eksplor lebih jauh lagi untuk durasi sebuah video bertahan dalam daftar trending dalam hal kategori video, channel, dan lainnya.
Most Viewed, Liked, and Disliked Video¶
Metrik ini tentu sangat umum dan dijunjung tinggi oleh para kreator konten YouTube. Dengan metrik tersebut, kita juga bisa membuat YouTube Rewind 2021 versi sederhana kita sendiri.
trending_by_title = filtered_trending.groupby("title")
trending_rewind = trending_by_title[["view", "like", "dislike"]].agg(["min", "max", "mean", "sum"])
trending_rewind
| view | like | dislike | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| min | max | mean | sum | min | max | mean | sum | min | max | mean | sum | |
| title | ||||||||||||
| "BABY R" BIKIN GEMES !!! RAFATHAR CEMBURU, SEMUA KELUARGA REBUTAN GENDONG... | 2280620.0 | 2637486.0 | 2.459053e+06 | 4918106.0 | 93348.0 | 101207.0 | 97277.500000 | 194555.0 | 1197.0 | 1286.0 | 1241.500000 | 2483.0 |
| "Emosi Rico Simanjutak" Saat Taisei Marukawa Berhasil Obrak Abrik Pertahanan Persija | 72434.0 | 116310.0 | 9.390625e+04 | 375625.0 | 990.0 | 1432.0 | 1228.500000 | 4914.0 | 40.0 | 61.0 | 47.750000 | 191.0 |
| "Grebek rumah harris vriza, dan percintaannya dengan R*cis” | 68879.0 | 163773.0 | 1.267565e+05 | 760539.0 | 5529.0 | 8714.0 | 7486.833333 | 44921.0 | 46.0 | 74.0 | 63.500000 | 381.0 |
| "Ini adalah IMPIAN bapa saya" - Tangisan Goh Liu Ying selepas tamat perjalanan di Tokyo | Nadi Arena | 503651.0 | 822845.0 | 7.171452e+05 | 3585726.0 | 6952.0 | 9144.0 | 8436.200000 | 42181.0 | 165.0 | 264.0 | 234.000000 | 1170.0 |
| "JANGAN DIKASARIN YA PAK.." CREW SETIA FARM SEDIH, PISAH SAMA GRANDONG | 1398186.0 | 1398186.0 | 1.398186e+06 | 1398186.0 | 44228.0 | 44228.0 | 44228.000000 | 44228.0 | 718.0 | 718.0 | 718.000000 | 718.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 🤟🏻aespa 'Savage' MV Reaction🤟🏻 | 1011999.0 | 1885538.0 | 1.567651e+06 | 10973554.0 | 127578.0 | 186596.0 | 165558.857143 | 1158912.0 | 1158.0 | 1812.0 | 1578.857143 | 11052.0 |
| 🥰 New Gadgets & Versatile Utensils For Home # 266🏠Appliances, Make Up, Smart Inventions スマートアプライアン | 330156.0 | 7334655.0 | 3.414214e+06 | 34142143.0 | 2822.0 | 58066.0 | 28320.700000 | 283207.0 | 283.0 | 7540.0 | 3517.500000 | 35175.0 |
| 🥰 New Gadgets & Versatile Utensils For Home # 303🏠Appliances, Make Up, Smart Inventions スマートアプライアン | 278942.0 | 1212522.0 | 7.948737e+05 | 5564116.0 | 2790.0 | 10212.0 | 6897.571429 | 48283.0 | 335.0 | 1335.0 | 878.000000 | 6146.0 |
| 🥰 New Gadgets & Versatile Utensils For Home # 309🏠Appliances, Make Up, Smart Inventions スマートアプライアン | 320084.0 | 1097903.0 | 7.562497e+05 | 4537498.0 | 3025.0 | 8759.0 | 6112.333333 | 36674.0 | 434.0 | 1115.0 | 806.500000 | 4839.0 |
| 🩸괴담회에 어서오세요🩸: 첫 번째 이야기 | WELCOME TO NCT’S HORROR NIGHTS | 1423178.0 | 2966798.0 | 2.629831e+06 | 36817634.0 | 316849.0 | 457809.0 | 429081.142857 | 6007136.0 | 479.0 | 1420.0 | 1238.357143 | 17337.0 |
6236 rows × 12 columns
Jika kita lihat data di atas, ada beberapa video yang jumlah minimal dan maksimum view, like, maupun dislike yang berbeda. Ini bisa saja dikarenakan video tersebut yang bertahan beberapa hari dalam trending, seperti video "Emosi Rico Simanjutak" Saat ... yang dimulai dengan jumlah view 72.434 pada awal masuk trending dan pada hari terakhir dalam trending mencapai jumlah view 116.310.
Sekarang, mari kita lihat jumlah maksimal view, like, dan dislike dari video teratas masing-masing tersebut dan bandingkan dengan pada saat awal masuk trending.
top_10_liked = trending_rewind["like"].sort_values("max", ascending=False).iloc[:10]
plt.figure(figsize=(15, 6))
plt.bar(
top_10_liked.index.to_series().apply(lambda title: "\n".join(wrap(title, width=10))),
top_10_liked["max"],
label="last like"
)
plt.bar(
top_10_liked.index.to_series().apply(lambda title: "\n".join(wrap(title, width=10))),
top_10_liked["min"],
label="start like"
)
plt.title("Most videos in trending list improves drastically in terms of likes", loc="left", y=1.1)
plt.xlabel("Number of Like")
plt.ylabel("Video Title")
plt.legend()
plt.grid(False)
plt.show()
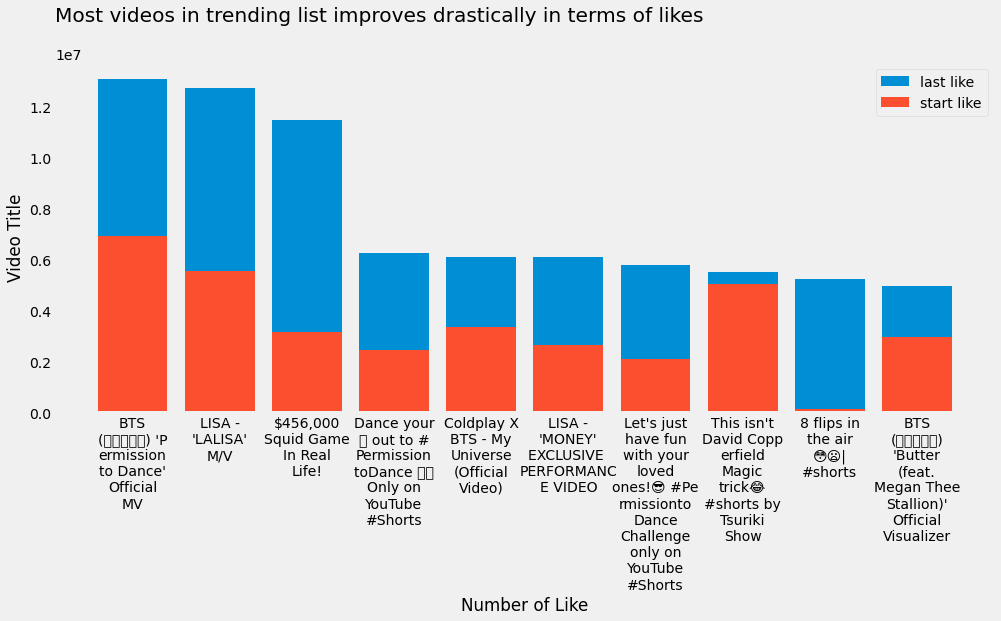
top_10_viewed = trending_rewind["view"].sort_values("max", ascending=False).iloc[:10]
plt.figure(figsize=(15, 6))
plt.bar(
top_10_viewed.index.to_series().apply(lambda title: "\n".join(wrap(title, width=10))),
top_10_viewed["max"],
label="last views"
)
plt.bar(
top_10_viewed.index.to_series().apply(lambda title: "\n".join(wrap(title, width=10))),
top_10_viewed["min"],
label="start views"
)
plt.title("Most videos in trending list improves drastically in terms of views, similar to likes", loc="left", y=1.1)
plt.xlabel("Number of Views")
plt.ylabel("Video Title")
plt.legend()
plt.grid(False)
plt.show()
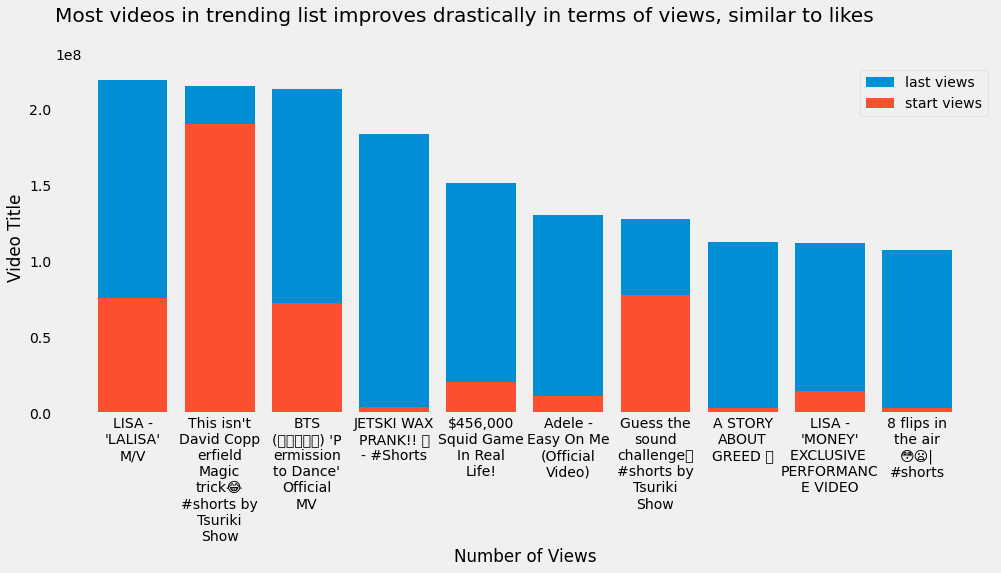
top_10_disliked = trending_rewind["dislike"].sort_values("max", ascending=False).iloc[:10]
plt.figure(figsize=(15, 6))
plt.bar(
top_10_disliked.index.to_series().apply(lambda title: "\n".join(wrap(title, width=10))),
top_10_disliked["max"],
label="last dislike"
)
plt.bar(
top_10_disliked.index.to_series().apply(lambda title: "\n".join(wrap(title, width=10))),
top_10_disliked["min"],
label="start dislike"
)
plt.title("Most disliked videos in trending list are of shorts and gain more dislikes", loc="left", y=1.1)
plt.ylabel("Number of Dislike")
plt.xlabel("Video Title")
plt.legend()
plt.grid(False)
plt.show()
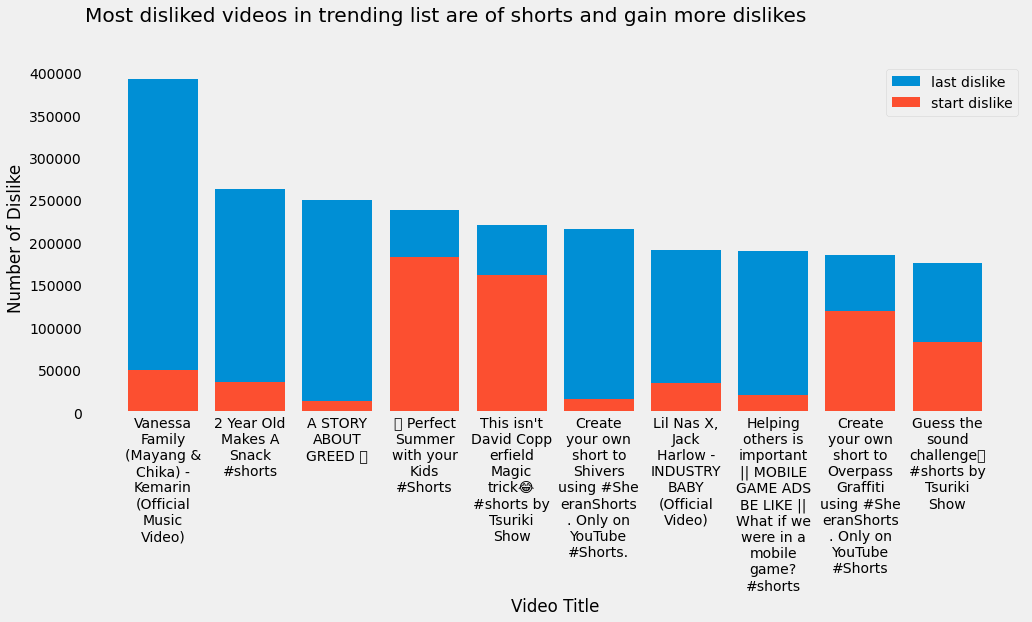
Tip
Kamu bisa melakukan eksplorasi lebih jauh lagi, seperti:
most viewed, liked, and disliked channels
video age from published until it’s trending
dan lainnya
Data Preparation¶
Data judul dan deskripsi yang akan kita proses nantinya termasuk ke dalam unstructured data atau teks. Pemrosesan data teks ini termasuk ke dalam bidang NLP (Natural Language Processing)
{kind=link}
Language Detection¶
Setelah melakukan eksplorasi, sekarang saatnya kita menyiapkan data yang akan digunakan untuk mengklasifikaskan kategori video, yaitu title dan description.
Attention
Kita hanya akan menggunakan video yang judul dan deskripsinya menggunakan bahasa Indonesia.
Karena kita hanya akan menggunakan teks berbahasa Indonesia, kita perlu menyaring mana yang berbahasa Indonesia dan mana yang bukan. Ada banyak library yang bisa kita gunakan, salah satunya adalah spacy. Tapi, karena alasan teknis, kita hanya akan menggunakan library yang lebih sederhana, yaitu langdetect.
Note
Jika kamu belum menginstall langdetect, install dengan perintah berikut:
pip install langdetect
Sebagai contoh, perhatikan sampel judul dan deskripsi video berikut.
sample = filtered_trending.sample(10, random_state=11)
sample[["title", "description"]]
| title | description | |
|---|---|---|
| 36912 | REAKSI ORANG JEPANG NYOBAIN JUS ALPUKAT | Begini reaksi Yoshi pertama kali nyobain jus a... |
| 38941 | Pengamen yang bisa mainin lagu ini gue kasih 1... | Pengamen sekarang keren-keren banget alatnya l... |
| 48089 | TREASURE - WEB DRAMA '남고괴담' CHARACTER INTERVIEW | 남고괴담 비하인드 스토리 구매하기\nhttps://weverseshop.onelin... |
| 24766 | (YB & Heiakim) Hello Goodbye - Sungha Jung X YB | (YB & Heiakim) Hello Goodbye - Sungha Jung X Y... |
| 50307 | Memecahkan Misteri Tantangan 1000 Kunci #2 Mul... | Jika ada brankas tertutup di depanmu, kau past... |
| 47844 | aespa 에스파 'Savage' Squid Game ver. Dance Practice | 'Savage' MV hits 100M views!\nThank you so muc... |
| 46357 | PMPL SEA Championship S4 | Superweekend 3 Day ... | SUPERWEEKEND TERAKHIR PENENTUAN 1 TIKET PERTAM... |
| 23245 | DAY6 (Even of Day) "Right Through Me(뚫고 지나가요)"... | DAY6 (Even of Day) "Right Through Me(뚫고 지나가요)"... |
| 24599 | DJ SETIAP YANG KU LAKUKAN UNTUK DIRIMU VIRAL ... | ----------------------------------------------... |
| 27364 | EP. 24 : Nekat Riding ke Area Rawan di Colombia | #WheelStory #MarioIroth #HondaAfricaTwin\n\nSe... |
sample["title_lang"] = sample.title.apply(lambda title: langdetect.detect(title.lower()))
sample["desc_lang"] = sample.description.apply(lambda desc: langdetect.detect(desc.lower()))
with pd.option_context("display.max_colwidth", 100):
display(sample[["title", "title_lang", "description", "desc_lang"]])
| title | title_lang | description | desc_lang | |
|---|---|---|---|---|
| 36912 | REAKSI ORANG JEPANG NYOBAIN JUS ALPUKAT | id | Begini reaksi Yoshi pertama kali nyobain jus alpukat! \nKalo di Jepang, alpukat dimakannya pake ... | id |
| 38941 | Pengamen yang bisa mainin lagu ini gue kasih 100 dollar | #Nantangin | id | Pengamen sekarang keren-keren banget alatnya lengkap.\nShoutout to pengamen-pengamen Bandung.\n\... | id |
| 48089 | TREASURE - WEB DRAMA '남고괴담' CHARACTER INTERVIEW | en | 남고괴담 비하인드 스토리 구매하기\nhttps://weverseshop.onelink.me/BZSY/9595f182 \n\n#TREASURE #트레저 #남고괴담 #TheMy... | en |
| 24766 | (YB & Heiakim) Hello Goodbye - Sungha Jung X YB | so | (YB & Heiakim) Hello Goodbye - Sungha Jung X YB\n\nTuning : Standard\n\nOriginal : https://youtu... | en |
| 50307 | Memecahkan Misteri Tantangan 1000 Kunci #2 Multi DO Challenge | id | Jika ada brankas tertutup di depanmu, kau pasti ingin tahu apa isinya! Pahlawan kita juga sangat... | id |
| 47844 | aespa 에스파 'Savage' Squid Game ver. Dance Practice | fr | 'Savage' MV hits 100M views!\nThank you so much for your love and support 😘\n\nListen and downlo... | en |
| 46357 | PMPL SEA Championship S4 | Superweekend 3 Day 1 | FULL TEAM INDONESIA DI SUPERWEEKEND | en | SUPERWEEKEND TERAKHIR PENENTUAN 1 TIKET PERTAMA MENUJU PMGC! Seteleh 2 hari Weekdays yang cukup ... | id |
| 23245 | DAY6 (Even of Day) "Right Through Me(뚫고 지나가요)" LIVE CLIP | en | DAY6 (Even of Day) "Right Through Me(뚫고 지나가요)" LIVE CLIP\n\nListen to DAY6 (Even of Day) "Right ... | en |
| 24599 | DJ SETIAP YANG KU LAKUKAN UNTUK DIRIMU VIRAL TIKTOK BAHAGIA SLOW BEAT SYAHDU | id | -------------------------------------------------------------\n Judul : DJ SETIAP YANG KU LAKUKA... | id |
| 27364 | EP. 24 : Nekat Riding ke Area Rawan di Colombia | id | #WheelStory #MarioIroth #HondaAfricaTwin\n\nSetelah Ecuador negara selanjutnya yang saya jelajah... | id |
Note
Perhatikan bahwa sebelum langdetect.detect, title dan deskripsi dijadikan lowercase. Ini dilakukan supaya langdetect dapat mendeteksi bahasa secara maksimal.
Ada beberapa kasus yang mungkin terjadi untuk deteksi bahasa pada judul dan deskripsi di atas:
Judul berbahasa Indonesia, sedangkan deskripsi dideteksi sebagai bahasa asing (yang mungkin seharusnya bahasa Indonesia)
Deksripsi dideteksi sebagai bahasa Indonesia, sedangkan judul berbahasa asing (yang mungkin seharusnya bahasa Indonesia)
Baik judul atau deskripsi dideteksi sebagai bahasa asing, yang seharusnya salah satu atau keduanya berbahasa Indonesia
Untuk kemungkinan ketiga, kita tidak akan menggunakan video yang judul dan deskripsinya dideteksi sebagai bahasa asing, meskipun seharusnya salah deteksi. Sekarang, mari kita deteksi bahasa untuk semua video dalam filtered_trending.
Pertama, kita akan buat fungsi yang akan mendeteksi bahasa dari sebuah teks sebagai berikut.
def detect_language(text):
"""Detect language of the `text`."""
try:
lang = langdetect.detect(text)
return lang
except:
return
def detect_language(text):
"""Detect language of the `text`."""
try:
lang = langdetect.detect(text)
return lang
except:
return
filtered_trending["title_lang"] = filtered_trending["title"].apply(detect_language)
filtered_trending["desc_lang"] = filtered_trending["description"].apply(detect_language)
filtered_trending[["title", "title_lang", "description", "desc_lang"]]
| title | title_lang | description | desc_lang | |
|---|---|---|---|---|
| 21322 | NCT DREAM 엔시티 드림 'Hello Future' MV | it | NCT DREAM's 1st Album Repackage "Hello Future"... | en |
| 21323 | PART 3 // SUTRISNO DAN ENDANG BAHAGIA | de | Find me on sosial media :\n\nInstagram : https... | en |
| 21324 | This isn't David Copperfield Magic trick😂 #sho... | en | Thank you for watching.\nSubscribe to Tsuriki ... | en |
| 21325 | Rizky Billar - Pemimpinmu | Official Music Video | it | Rizky Billar - Pemimpinmu | Official Music Vid... | id |
| 21326 | Ini Pengakuan Pengemudi Pajero usai Rusak dan ... | id | Polisi menangkap pengemudi SUV yang merusak da... | id |
| ... | ... | ... | ... | ... |
| 52916 | ARSY DAN THALIA ONSU DUET SAMPAI BIKIN RAFFI A... | de | Gemes! Arsy dan Thalia Putri Onsu duet nyanyi ... | id |
| 52918 | Beli barang aneh yang dijual ONLINE Episode 20! | id | Banyak lap nya.\n\nDapatkan Betadine Cold Defe... | id |
| 52919 | Layangan Putus | Highlight EP02 Senyum Bahagia... | id | Yuk tonton full episodenya, GRATIS melalui app... | id |
| 52920 | PAULA LEMES , GA BISA NGOMONG APA2.. | hu | =================================\r\n\r\nSocia... | id |
| 52921 | PRANK RICIS & TEUKU RYAN YG LAGI HONEYMOON! NG... | en | Hi baby!\n\nDi video ini aku akan ajak kalian ... | en |
30194 rows × 4 columns
Setelah kita selesai mendeteksi bahasa pada title dan description, langkah selanjutnya adalah membuang data yang title atau description bukan id, yaitu tidak berbahasa Indonesia.
indo_trending = filtered_trending.loc[
(filtered_trending.title_lang == "id") | (filtered_trending.desc_lang == "id")
]
with pd.option_context("display.max_columns", None):
display(indo_trending.sample(10))
| publish_time | channel_id | title | description | thumbnail_url | thumbnail_width | thumbnail_height | channel_name | tags | category_id | live_status | local_title | local_description | duration | dimension | definition | caption | license_status | allowed_region | blocked_region | view | like | dislike | favorite | comment | trending_time | title_lang | desc_lang | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 30566 | 2021-08-12 09:45:03+00:00 | UC7NjHQFW-iD0nZy2javtbsA | panasin motor | #shorts minta tolong istri untuk panasin motor... | NaN | NaN | NaN | WILSON SINAI | ['Wilson Sinai', 'kocak', 'lucu', 'humor', 'da... | 23 | none | panasin motor | #shorts minta tolong istri untuk panasin motor... | PT39S | 2d | hd | False | True | NaN | NaN | 798582.0 | 17145.0 | 3211.0 | 0 | 74.0 | 2021-08-16 06:01:24.369770+00:00 | tl | id |
| 44534 | 2021-10-24 09:02:41+00:00 | UCM3SMB1jINy_NxH1O01z5gA | [2021] Free Fire Indonesia Masters 2021 Fall -... | Hi Survivors!\n\nHari ini adalah malam penentu... | NaN | NaN | NaN | Garena Free Fire Indonesia | NaN | 20 | none | [2021] Free Fire Indonesia Masters 2021 Fall -... | Hi Survivors!\n\nHari ini adalah malam penentu... | PT4H11M56S | 2d | hd | False | False | NaN | NaN | 1168427.0 | 52004.0 | 1087.0 | 0 | 1324.0 | 2021-10-25 06:00:43.895693+00:00 | en | id |
| 47788 | 2021-11-07 01:00:08+00:00 | UCRWHpR_TJiE_2uKf8ivsZQg | 24 JAM PAKE BUNDLE SERBA MERAH HITAM BARENG EV... | Halo gaes, balik lagi sama aku nih. Maaf ya ud... | NaN | NaN | NaN | QUEN | NaN | 20 | none | 24 JAM PAKE BUNDLE SERBA MERAH HITAM BARENG EV... | Halo gaes, balik lagi sama aku nih. Maaf ya ud... | PT26M45S | 2d | hd | False | True | NaN | NaN | 362630.0 | 32166.0 | 467.0 | 0 | 1482.0 | 2021-11-10 06:02:22.517683+00:00 | en | id |
| 28751 | 2021-08-03 02:00:12+00:00 | UCA1j_75REY9xurdvnr_H8ig | Elsa Pitaloka - Haruskah Aku Mati (Official Mu... | Elsa Pitaloka - Haruskah Aku Mati (Official Mu... | NaN | NaN | NaN | Teras Musik | ['elsa pitaloka', 'teras musik', 'haruskah aku... | 10 | none | Elsa Pitaloka - Haruskah Aku Mati (Official Mu... | Elsa Pitaloka - Haruskah Aku Mati (Official Mu... | PT5M30S | 2d | hd | False | True | NaN | NaN | 418203.0 | 5644.0 | 269.0 | 0 | 1077.0 | 2021-08-07 06:00:58.726850+00:00 | et | id |
| 41119 | 2021-09-29 09:34:29+00:00 | UCsE7IVpsU-jk6vAdBP9ZREg | AKHIRNYA PUCUK | MPL SEASON 8 HIGHLIGHT | RRQ Hoshi berhasil membalaskan kekalahannya ke... | NaN | NaN | NaN | Team RRQ | ['team rrq', 'rrq', 'rex regum qeon', 'viva rr... | 20 | none | AKHIRNYA PUCUK | MPL SEASON 8 HIGHLIGHT | RRQ Hoshi berhasil membalaskan kekalahannya ke... | PT22M21S | 2d | hd | True | True | NaN | NaN | 1333749.0 | 70552.0 | 673.0 | 0 | 4964.0 | 2021-10-07 06:00:54.443732+00:00 | en | id |
| 39133 | 2021-09-21 07:00:13+00:00 | UCmtAg_U0wvmWdxTlceISdEw | Kisah Berat Pascol dari Jadi Kuli Sampe Ditudu... | Subsrcibe channel @Pascol Kintil @LuanLuan \nF... | NaN | NaN | NaN | Jonathan Liandi | ['MOBILELEGENDS', 'MOBILELEGENDSINDONESIA', 'M... | 20 | none | Kisah Berat Pascol dari Jadi Kuli Sampe Ditudu... | Subsrcibe channel @Pascol Kintil @LuanLuan \nF... | PT34M52S | 2d | hd | False | True | NaN | NaN | 3696853.0 | 187571.0 | 2362.0 | 0 | 13474.0 | 2021-09-28 06:01:04.886400+00:00 | id | id |
| 29009 | 2021-08-02 13:00:06+00:00 | UCSNr4Dv_TqeFEyG157HhRsQ | INILAH YANG AKAN TERJADI DI MALAM SATU SURO 20... | #malamsatusuro #rezarahasia | NaN | NaN | NaN | Reza Rahasia | ['rezarahasia', 'malamsatusuro', 'nyawiji', 'n... | 25 | none | INILAH YANG AKAN TERJADI DI MALAM SATU SURO 20... | #malamsatusuro #rezarahasia | PT15M41S | 2d | hd | False | True | NaN | NaN | 281177.0 | 5218.0 | 281.0 | 0 | 810.0 | 2021-08-08 06:01:02.781399+00:00 | en | id |
| 35877 | 2021-08-31 09:49:16+00:00 | UC2EA8X3TaqfF7fRwOI580kw | MASUK KANDANG HARIMAU !! LANGSUNG JADI TARGET 😱😱 | Untuk lihat tingkah lucu anabul kesayangan kit... | NaN | NaN | NaN | The Golden Family | ['thegoldenfamily', 'bimaaryo', 'beemzaryo', '... | 15 | none | MASUK KANDANG HARIMAU !! LANGSUNG JADI TARGET 😱😱 | Untuk lihat tingkah lucu anabul kesayangan kit... | PT31M42S | 2d | hd | False | True | NaN | NaN | 1651417.0 | 30546.0 | 704.0 | 0 | 2310.0 | 2021-09-11 06:00:56.866666+00:00 | de | id |
| 24215 | 2021-07-10 02:00:32+00:00 | UC7GWXKxiy9_AU9TytEh00eg | Nenek Setan - Selalu Memaksaku Ikut ke Kuburan... | Join this channel to get access to perks:\nhtt... | NaN | NaN | NaN | Rizky Riplay | ['hantu', 'rizky riplay', 'kartun', 'kartun ha... | 1 | none | Nenek Setan - Selalu Memaksaku Ikut ke Kuburan... | Join this channel to get access to perks:\nhtt... | PT4M49S | 2d | hd | False | True | NaN | NaN | 337259.0 | 9292.0 | 348.0 | 0 | 2394.0 | 2021-07-15 06:01:12.512599+00:00 | id | id |
| 28042 | 2021-08-01 02:00:16+00:00 | UChFv0WPR47xMAPpCJWUgk1Q | Esa Risty - Bojo Biduan (Official Music Video)... | Official Music Video Esa Risty Bojo Biduan | (... | NaN | NaN | NaN | Esa Risty Official | ['#EsaRisty', '#BojoBiduan', '#DJSantuy', '#Te... | 10 | none | Esa Risty - Bojo Biduan (Official Music Video)... | Official Music Video Esa Risty Bojo Biduan | (... | PT5M45S | 2d | hd | False | True | NaN | NaN | 82107.0 | 2742.0 | 47.0 | 0 | 730.0 | 2021-08-03 06:00:50.958191+00:00 | es | id |
Feature Extraction¶
Selanjutnya, kita akan membuang semua fitur/kolom yang tidak diperlukan. Dalam hal ini, kita hanya akan memerlukan title, descrption, dan category_id. Sehingga, kolom lainnya akan dibuang.
data = indo_trending[["title", "description", "category_id"]].reset_index(drop=True)
data
| title | description | category_id | |
|---|---|---|---|
| 0 | Rizky Billar - Pemimpinmu | Official Music Video | Rizky Billar - Pemimpinmu | Official Music Vid... | 10 |
| 1 | Ini Pengakuan Pengemudi Pajero usai Rusak dan ... | Polisi menangkap pengemudi SUV yang merusak da... | 25 |
| 2 | Aksi Demo Tolak Kedatangan Jokowi di Kendari B... | Tanggal Tayang: 30/06/2021\n\nProgram berita h... | 25 |
| 3 | PERTAMA KALI LIAT SAPI SEGEDE GINI, DINAIKIN D... | Assalamualaikum gaeess..! sudah nonton video s... | 15 |
| 4 | PODKESMAS SAMPAI GA NYAMAN DIBAHAS DISINI - To... | Talk show malam yang akan memberikan informasi... | 24 |
| ... | ... | ... | ... |
| 17717 | Nazia Marwiana - Kehadiran Cinta (Official Mus... | Official Music Live from Nazia Marwiana - Keha... | 10 |
| 17718 | ARSY DAN THALIA ONSU DUET SAMPAI BIKIN RAFFI A... | Gemes! Arsy dan Thalia Putri Onsu duet nyanyi ... | 24 |
| 17719 | Beli barang aneh yang dijual ONLINE Episode 20! | Banyak lap nya.\n\nDapatkan Betadine Cold Defe... | 28 |
| 17720 | Layangan Putus | Highlight EP02 Senyum Bahagia... | Yuk tonton full episodenya, GRATIS melalui app... | 1 |
| 17721 | PAULA LEMES , GA BISA NGOMONG APA2.. | =================================\r\n\r\nSocia... | 24 |
17722 rows × 3 columns
Duplicates¶
Jika kita perhatikan secara teliti, kita akan temukan bahwa ada beberapa title ataupun desription yang duplikat. Hal in dikarenakan adanya kemungkinan sebuah video masuk dalam daftar trending pada hari yang berbeda. Untuk alasan fairness, kita akan membuang beberapa duplikat tersebut.
data.drop_duplicates(subset="title", inplace=True)
data.reset_index(drop=True, inplace=True)
data.shape
(3656, 3)
Setelah membuang beberapa duplikat, hanya tersisa 3643 baris data saja yang akan kita gunakan pada fase modeling.
Feature Engineering¶
Kita tahu bahwa biasanya kreator konten suka menggunakan emoji di judul ataupun deskripsi video mereka. Emoji ini mungkin bisa menggambarkan judul dan deskripsi. Oleh karena itu, kita akan coba mengubah emoji tersebut ke dalam bentuk teks menggunakan library emoji.
Note
Silakan install terlebih dahulu library emoji dengan perintah berikut.
pip install emoji
Sebelum itu, mari kita ada berapa judul yang menggunakan emoji di dalamnya.
list_emoji = [e for e in emoji.UNICODE_EMOJI.get("en")]
count = 0
for em in list_emoji:
for title in data.title:
if em in title:
count += 1
print("How many titles use emoji?", count)
How many titles use emoji? 525
Ternyata ada 538 video yang judul nya menggunakan emoji. Kita akan buat fungsi untuk menerjemahkan emoji di dalam judul sebagai berikut.
def demojize(text):
for em in list_emoji:
if em in text:
em_text = emoji.demojize(em)
text = text.replace(em, " " + em_text + " ")
return text
def demojize(text):
for em in list_emoji:
if em in text:
em_text = emoji.demojize(em)
text = text.replace(em, " " + em_text + " ")
return text
data["title_emoji"] = data.title.apply(demojize)
Mari kita lihat beberapa sampel judul yang menggunakan emoji dan bagaimana bentuk representasi teksnya.
title_with_emoji_idx = [
idx for idx in range(len(data.title))
for em in list_emoji
if em in data.loc[idx, "title"]
]
with pd.option_context("display.max_colwidth", 100):
display(data.loc[title_with_emoji_idx])
| title | description | category_id | title_emoji | |
|---|---|---|---|---|
| 34 | Dari Jendela Smp : GREGETTT...Wih kelihatannya Wulan jadi primadona di SMA Merdeka Mandiri nih...❤ | Saksikan #DariJendelaSMP Setiap Hari Pkl. 16.40 WIB hanya di @Surya Citra Televisi (SCTV) \n@sin... | 24 | Dari Jendela Smp : GREGETTT...Wih kelihatannya Wulan jadi primadona di SMA Merdeka Mandiri nih..... |
| 79 | BIKIN CEWEK TERPESONA 😍 Aksi Heroik Driver Muda Menolong Sopir Yang Kesulitan di Sitinjau Lauik | Aksi heroik driver muda membantu sopir minibus yang kesulitan di Sitinjau Lauik\n\ninstagram : h... | 2 | BIKIN CEWEK TERPESONA :smiling_face_with_heart-eyes: Aksi Heroik Driver Muda Menolong Sopir Ya... |
| 81 | 15 MENIT MEMBAKAR LEMAK 1 Kg !!! 24 Jam TIMBANGAN TURUN ✅ ✅ ✅ | 15 menit membakar lemak, ok ! siapa yg workout mengharapkan bisa membakar 1 kg lemak dalam 15 me... | 26 | 15 MENIT MEMBAKAR LEMAK 1 Kg !!! 24 Jam TIMBANGAN TURUN :check_mark_button: :check_mark_butto... |
| 147 | WHY‼️ SAYA DISOMASI, TOLOOONG...- Deddy Corbuzier Podcast | #somasi #odgj #podcast\nTEMAN TEMAN KONTEN CREATOR, JANGAN TAKUT BERKARYA SELAMA TUJUAN KALIAN B... | 24 | WHY :double_exclamation_mark: SAYA DISOMASI, TOLOOONG...- Deddy Corbuzier Podcast |
| 147 | WHY‼️ SAYA DISOMASI, TOLOOONG...- Deddy Corbuzier Podcast | #somasi #odgj #podcast\nTEMAN TEMAN KONTEN CREATOR, JANGAN TAKUT BERKARYA SELAMA TUJUAN KALIAN B... | 24 | WHY :double_exclamation_mark: SAYA DISOMASI, TOLOOONG...- Deddy Corbuzier Podcast |
| ... | ... | ... | ... | ... |
| 3541 | Bibi Korea sakit, obatnya makan rasa pedas Indonesia!!🔥🔥 | #SuwirIkan#수위르이깐\nMukbang ikan + sambal!!! | 24 | Bibi Korea sakit, obatnya makan rasa pedas Indonesia!! :fire: :fire: |
| 3582 | 💚Indonesian NCTzens Aku Bersamamu💚 | Tokopedia WIB: Indonesia K-Pop Awards Behind | #NCTDREAM #Tokopedia #WIBKpopAwards #TokopediaWIB #behind\n\nNCT DREAM Official\nhttps://www.you... | 22 | :green_heart: Indonesian NCTzens Aku Bersamamu :green_heart: | Tokopedia WIB: Indonesia K-Pop ... |
| 3619 | Astaga..Konro bakar Indonesia bisa menyembuhkan pasien ya..?!🤣 | #IndonesianFood#KonroBakar#꽁로바까르\nMukbang Konro bakar!!!!!!!!!!!!!!!!!\nBibi kangkung auto seman... | 24 | Astaga..Konro bakar Indonesia bisa menyembuhkan pasien ya..?! :rolling_on_the_floor_laughing: |
| 3622 | OSHICIS LENGKAP SAMA PARA SUAMI DI APARTEMEN RYAN⁉️ ADA APA INI⁉️ | #OSHICIS #RicisRyan \n\n\nTonton jugaa Video sebelumnya yaa‼️🔥😍\n\nhttps://youtu.be/mnalhhFN0no\... | 22 | OSHICIS LENGKAP SAMA PARA SUAMI DI APARTEMEN RYAN :exclamation_question_mark: ADA APA INI :excl... |
| 3622 | OSHICIS LENGKAP SAMA PARA SUAMI DI APARTEMEN RYAN⁉️ ADA APA INI⁉️ | #OSHICIS #RicisRyan \n\n\nTonton jugaa Video sebelumnya yaa‼️🔥😍\n\nhttps://youtu.be/mnalhhFN0no\... | 22 | OSHICIS LENGKAP SAMA PARA SUAMI DI APARTEMEN RYAN :exclamation_question_mark: ADA APA INI :excl... |
525 rows × 4 columns
Karena kita sudah mendapatkan representasi emoji pada kolom title_emoji, kita tidak memerlukan kolom title lagi. Sehingga, kita bisa buang kolom tersebut.
data.drop(columns="title", inplace=True)
Selanjutnya, kita akan melakukan hal yang sama pada kolom description untuk kasus emoji.
Eksplorasi
Ada berapa video yang deskripsinya menggunakan emoji?
desc_with_emoji_idx = [
idx for idx in range(len(data.description))
for em in list_emoji
if em in data.loc[idx, "description"]
]
data["desc_emoji"] = data.description.apply(demojize)
with pd.option_context("display.max_colwidth", 100):
display(data.loc[desc_with_emoji_idx])
| description | category_id | title_emoji | desc_emoji | |
|---|---|---|---|---|
| 0 | Rizky Billar - Pemimpinmu | Official Music Video\n\nSurprise Untuk Dede Lesti :\nhttps://youtu.b... | 10 | Rizky Billar - Pemimpinmu | Official Music Video | Rizky Billar - Pemimpinmu | Official Music Video\n\nSurprise Untuk Dede Lesti :\nhttps://youtu.b... |
| 8 | #LestiBawaAkuKePenghulu #Lesti #MusicVideo #LiveAcoustic\n\nAura bahagia semakin terpancar denga... | 10 | Lesti - Bawa Aku Ke Penghulu | Live Acoustic Version | #LestiBawaAkuKePenghulu #Lesti #MusicVideo #LiveAcoustic\n\nAura bahagia semakin terpancar denga... |
| 11 | Title: Sempurnakan Hariku \nArtist: Rey Mbayang\nComposser: Rey Mbayang, Trakast\nMusic Arranger... | 10 | Rey Mbayang - Sempurnakan Hariku (Official Music Video) | Title: Sempurnakan Hariku \nArtist: Rey Mbayang\nComposser: Rey Mbayang, Trakast\nMusic Arranger... |
| 12 | Title: Apa Kabar Mantan\nArtist: Yeni Inka\nSongwriter: Yonanda NDX\n\nFollow juga kita disini y... | 10 | Yeni Inka - Apa Kabar Mantan (Official Music Video ANEKA SAFARI) | JOOX ORIGINAL | Title: Apa Kabar Mantan\nArtist: Yeni Inka\nSongwriter: Yonanda NDX\n\nFollow juga kita disini y... |
| 12 | Title: Apa Kabar Mantan\nArtist: Yeni Inka\nSongwriter: Yonanda NDX\n\nFollow juga kita disini y... | 10 | Yeni Inka - Apa Kabar Mantan (Official Music Video ANEKA SAFARI) | JOOX ORIGINAL | Title: Apa Kabar Mantan\nArtist: Yeni Inka\nSongwriter: Yonanda NDX\n\nFollow juga kita disini y... |
| ... | ... | ... | ... | ... |
| 3643 | 🎥 HIGHLIGHTS | 🇸🇬 Singapore 3-0 Myanmar 🇲🇲\n\n🦁 A brace from Ikhsan Fandi and one from Safuwan B... | 17 | Singapore 3-0 Myanmar (AFF Suzuki Cup 2020: Group Stage) | :movie_camera: HIGHLIGHTS | :Singapore: Singapore 3-0 Myanmar :Myanmar_(Burma): \n\n :lion:... |
| 3643 | 🎥 HIGHLIGHTS | 🇸🇬 Singapore 3-0 Myanmar 🇲🇲\n\n🦁 A brace from Ikhsan Fandi and one from Safuwan B... | 17 | Singapore 3-0 Myanmar (AFF Suzuki Cup 2020: Group Stage) | :movie_camera: HIGHLIGHTS | :Singapore: Singapore 3-0 Myanmar :Myanmar_(Burma): \n\n :lion:... |
| 3643 | 🎥 HIGHLIGHTS | 🇸🇬 Singapore 3-0 Myanmar 🇲🇲\n\n🦁 A brace from Ikhsan Fandi and one from Safuwan B... | 17 | Singapore 3-0 Myanmar (AFF Suzuki Cup 2020: Group Stage) | :movie_camera: HIGHLIGHTS | :Singapore: Singapore 3-0 Myanmar :Myanmar_(Burma): \n\n :lion:... |
| 3643 | 🎥 HIGHLIGHTS | 🇸🇬 Singapore 3-0 Myanmar 🇲🇲\n\n🦁 A brace from Ikhsan Fandi and one from Safuwan B... | 17 | Singapore 3-0 Myanmar (AFF Suzuki Cup 2020: Group Stage) | :movie_camera: HIGHLIGHTS | :Singapore: Singapore 3-0 Myanmar :Myanmar_(Burma): \n\n :lion:... |
| 3644 | ▶ Follow aku!\nInstagram - https://www.instagram.com/ekooju/\nOura Store - https://www.instagram... | 20 | Gerrard Wijaya Si Publik Paling Kreatif Penemu BUG2 Aneh!! - Rect TikTok #21 | :play_button: Follow aku!\nInstagram - https://www.instagram.com/ekooju/\nOura Store - https:/... |
1825 rows × 4 columns
Kita juga bisa buang kolom description karena kita tidak membutuhkannya lagi.
data.drop(columns="description", inplace=True)
Selanjutnya, kita akan gabungkan title_emoji dan desc_emoji menjadi satu teks yang panjang ke dalam kolom all_text. Kolom ini yang selanjutnya akan kita gunakan untuk membentuk matriks TF-IDF.
data["all_text"] = data["title_emoji"] + " " + data["desc_emoji"]
Untuk membentuk matrik TF-IDF, kita akan gunakan bantuan scikit-learn berdasarkan data training.
Note
Kita akan bagi data terlebih dahulu menjadi training dan development.
# data split
X_train, X_dev, y_train, y_dev = train_test_split(
data["all_text"], data["category_id"],
test_size=.2,
stratify=data["category_id"],
random_state=11
)
training_size = X_train.shape[0]
dev_size = X_dev.shape[0]
print(f"{training_size = }.. {dev_size = }")
# define vectorizer
vectorizer = TfidfVectorizer(
min_df=.015,
max_df=.7,
ngram_range=(1, 1),
)
# generate tf-idf matrix
train_tfidf = vectorizer.fit_transform(X_train)
dev_tfidf = vectorizer.transform(X_dev)
print("Got train tf-idf with shape:", train_tfidf.shape)
print("Got dev tf-idf with shape:", dev_tfidf.shape)
# convert to dataframe
train_tfidf = pd.DataFrame(train_tfidf.toarray(), columns=vectorizer.get_feature_names_out())
dev_tfidf = pd.DataFrame(dev_tfidf.toarray(), columns=vectorizer.get_feature_names_out())
training_size = 2924.. dev_size = 732
Got train tf-idf with shape: (2924, 963)
Got dev tf-idf with shape: (732, 963)
with pd.option_context("display.max_columns", 100):
display(train_tfidf.sample(5))
| 00 | 01 | 02 | 03 | 04 | 06 | 07 | 08 | 09 | 10 | 100 | 11 | 12 | 1212 | 123 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 1dvz1au | 1gxqz9s | 1st | 20 | 2020 | 2021 | 21 | 22 | 23 | 24 | 26 | 28 | 2oukyag | 2yfofxp | 30 | 31 | 3ws0f48 | 40 | 45 | 50 | 62 | about | acara | account | aceh | ada | adalah | adanya | ... | under | untuk | untukmu | up | update | us | user | utama | utm_medium | vanessa | via | video | videonya | videos | vidio | viral | voc | vocal | vs | vt | wa | waktu | wanita | warga | warna | watch | watching | web | website | wes | wib | with | withyoutube | wong | www | ya | yaa | yah | yaitu | yang | yen | yeni | yeniinka | yg | you | your | youtu | youtube | yuk | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 818 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.023878 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | ... | 0.0 | 0.009255 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.021265 | 0.009215 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.809178 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.327897 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.014655 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.387096 | 0.0 |
| 2686 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.234669 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | ... | 0.0 | 0.085208 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.121919 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.134172 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.067462 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 |
| 1519 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.089944 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | ... | 0.0 | 0.167835 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.167108 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.079284 | 0.048625 | 0.0 | 0.0 | 0.0 | 0.132879 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 |
| 70 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | ... | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.106797 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 |
| 1111 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.085406 | 0.0 | 0.0 | 0.160202 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.060704 | 0.0 | ... | 0.0 | 0.036278 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.036121 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.085687 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.086167 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.206913 | 0.0 |
5 rows × 963 columns
Modeling¶
Setelah mempersiapkan data untuk training, sekarang saatnya kita lakukan training menggunakan beberapa model. Model yang akan kita coba untuk mengklasifikasi kategori video YouTube seperti:
Logistic Regression
Naive Bayes
SVM
Decision Tree
Random Forest
Attention
Penjelasan tentang bagaimana model bekerja secara detail mungkin tidak akan di bahas di sini. Jika tertarik, silakan membaca literatur yang tersedia secara online.
Model Training & Evaluation¶
Pertama, mari kita definisikan beberapa model tersebut dan menggunakan default hyperparameter dari scikit-learn terlebih dahulu.
dict_models = {
"logistic_regression": LogisticRegression(),
"naive_bayes": MultinomialNB(),
"svm": LinearSVC(random_state=11),
"decision_tree": DecisionTreeClassifier(random_state=11),
"random_forest": RandomForestClassifier(random_state=11)
}
for model in dict_models.values():
print(f"-- {model.__class__.__name__} --")
model.fit(train_tfidf, y_train)
y_pred = model.predict(dev_tfidf)
print("Reports on dev set:", classification_report(y_dev, y_pred), sep="\n")
-- LogisticRegression --
Reports on dev set:
precision recall f1-score support
1 0.90 0.45 0.60 20
2 0.93 0.70 0.80 20
10 0.94 0.92 0.93 142
15 1.00 0.43 0.60 7
17 1.00 0.36 0.53 14
19 0.00 0.00 0.00 5
20 0.92 0.89 0.91 54
22 0.60 0.57 0.58 70
23 1.00 0.84 0.92 32
24 0.74 0.92 0.82 228
25 0.83 0.96 0.89 99
26 1.00 0.25 0.40 16
27 1.00 0.12 0.22 8
28 1.00 0.57 0.73 7
29 1.00 0.80 0.89 10
accuracy 0.82 732
macro avg 0.86 0.59 0.65 732
weighted avg 0.83 0.82 0.80 732
-- MultinomialNB --
Reports on dev set:
precision recall f1-score support
1 1.00 0.15 0.26 20
2 1.00 0.25 0.40 20
10 0.92 0.91 0.91 142
15 0.00 0.00 0.00 7
17 1.00 0.36 0.53 14
19 0.00 0.00 0.00 5
20 0.88 0.69 0.77 54
22 0.62 0.44 0.52 70
23 1.00 0.53 0.69 32
24 0.63 0.88 0.73 228
25 0.75 0.98 0.85 99
26 0.73 0.50 0.59 16
27 0.00 0.00 0.00 8
28 0.00 0.00 0.00 7
29 1.00 0.80 0.89 10
accuracy 0.74 732
macro avg 0.63 0.43 0.48 732
weighted avg 0.75 0.74 0.71 732
-- LinearSVC --
Reports on dev set:
precision recall f1-score support
1 0.76 0.65 0.70 20
2 0.94 0.80 0.86 20
10 0.96 0.93 0.94 142
15 1.00 0.86 0.92 7
17 0.78 0.50 0.61 14
19 1.00 0.80 0.89 5
20 0.89 0.94 0.92 54
22 0.74 0.80 0.77 70
23 0.88 0.88 0.88 32
24 0.88 0.89 0.89 228
25 0.84 0.94 0.89 99
26 0.83 0.62 0.71 16
27 0.86 0.75 0.80 8
28 1.00 0.71 0.83 7
29 1.00 0.80 0.89 10
accuracy 0.87 732
macro avg 0.89 0.79 0.83 732
weighted avg 0.87 0.87 0.87 732
-- DecisionTreeClassifier --
Reports on dev set:
precision recall f1-score support
1 0.56 0.45 0.50 20
2 1.00 0.85 0.92 20
10 0.94 0.83 0.88 142
15 1.00 0.57 0.73 7
17 0.78 0.50 0.61 14
19 0.67 0.80 0.73 5
20 0.73 0.76 0.75 54
22 0.59 0.60 0.60 70
23 0.68 0.84 0.75 32
24 0.76 0.84 0.80 228
25 0.77 0.79 0.78 99
26 0.82 0.56 0.67 16
27 0.67 0.75 0.71 8
28 1.00 0.57 0.73 7
29 0.80 0.80 0.80 10
accuracy 0.77 732
macro avg 0.78 0.70 0.73 732
weighted avg 0.78 0.77 0.77 732
-- RandomForestClassifier --
Reports on dev set:
precision recall f1-score support
1 1.00 0.60 0.75 20
2 1.00 0.90 0.95 20
10 0.94 0.93 0.94 142
15 1.00 0.86 0.92 7
17 1.00 0.50 0.67 14
19 1.00 0.80 0.89 5
20 0.89 0.93 0.91 54
22 0.96 0.79 0.87 70
23 0.94 0.91 0.92 32
24 0.81 0.93 0.87 228
25 0.86 0.97 0.91 99
26 1.00 0.56 0.72 16
27 1.00 0.75 0.86 8
28 1.00 0.57 0.73 7
29 1.00 0.80 0.89 10
accuracy 0.89 732
macro avg 0.96 0.79 0.85 732
weighted avg 0.90 0.89 0.88 732
Hyperparameter Tuning¶
Dari 5 model tersebut, 2 model yang paling bagus akurasinya adalah LinearSVC dan RandomForestClassifier. Oleh karena itu, kita akan coba melakukan hyperparameter tuning untuk kedua model tersebut, dengan harapan performa model akan semakin bagus. Kita akan menggunakan grid search untuk menentukan hyperparameter yang paling optimal.
LinearSVC¶
svm_grid_search = GridSearchCV(
dict_models["svm"],
{"C": (10, 1, .1, .05, .01)},
)
svm_grid_search.fit(train_tfidf, y_train)
svm_pred_dev = svm_grid_search.predict(dev_tfidf)
print("Reports on train set:",
classification_report(
y_train,
svm_grid_search.predict(train_tfidf)
), sep="\n")
print("Reports on dev set:", classification_report(y_dev, svm_pred_dev), sep="\n")
Reports on train set:
precision recall f1-score support
1 0.99 0.94 0.96 81
2 1.00 1.00 1.00 80
10 0.96 0.99 0.98 566
15 1.00 1.00 1.00 26
17 0.95 0.98 0.96 54
19 1.00 1.00 1.00 19
20 0.98 0.99 0.98 216
22 0.97 0.90 0.93 279
23 0.99 0.98 0.98 126
24 0.96 0.96 0.96 913
25 0.96 0.99 0.98 395
26 0.92 0.91 0.91 65
27 1.00 1.00 1.00 34
28 1.00 1.00 1.00 28
29 1.00 0.98 0.99 42
accuracy 0.97 2924
macro avg 0.98 0.97 0.98 2924
weighted avg 0.97 0.97 0.97 2924
Reports on dev set:
precision recall f1-score support
1 0.76 0.65 0.70 20
2 0.94 0.80 0.86 20
10 0.96 0.93 0.94 142
15 1.00 0.86 0.92 7
17 0.78 0.50 0.61 14
19 1.00 0.80 0.89 5
20 0.89 0.94 0.92 54
22 0.74 0.80 0.77 70
23 0.88 0.88 0.88 32
24 0.88 0.89 0.89 228
25 0.84 0.94 0.89 99
26 0.83 0.62 0.71 16
27 0.86 0.75 0.80 8
28 1.00 0.71 0.83 7
29 1.00 0.80 0.89 10
accuracy 0.87 732
macro avg 0.89 0.79 0.83 732
weighted avg 0.87 0.87 0.87 732
svm_grid_search.best_params_
{'C': 1}
RandomForestClassifier¶
random_forest_grid_search = GridSearchCV(
dict_models["random_forest"],
{
"n_estimators": (10, 20, 25, 50, 75, 100, 125),
"max_depth": (5, 10, 25, 50),
}
)
random_forest_grid_search.fit(train_tfidf, y_train)
random_forest_pred = random_forest_grid_search.predict(dev_tfidf)
print("Reports on train set:",
classification_report(
y_train,
random_forest_grid_search.predict(train_tfidf)
),
sep="\n"
)
print("Reports on dev set:", classification_report(y_dev, random_forest_pred), sep="\n")
Reports on train set:
precision recall f1-score support
1 1.00 0.99 0.99 81
2 1.00 0.96 0.98 80
10 1.00 1.00 1.00 566
15 1.00 0.96 0.98 26
17 0.96 0.98 0.97 54
19 1.00 0.89 0.94 19
20 1.00 1.00 1.00 216
22 1.00 0.98 0.99 279
23 1.00 0.99 1.00 126
24 0.98 1.00 0.99 913
25 1.00 1.00 1.00 395
26 1.00 0.98 0.99 65
27 1.00 1.00 1.00 34
28 1.00 1.00 1.00 28
29 1.00 1.00 1.00 42
accuracy 0.99 2924
macro avg 1.00 0.98 0.99 2924
weighted avg 0.99 0.99 0.99 2924
Reports on dev set:
precision recall f1-score support
1 1.00 0.55 0.71 20
2 1.00 0.90 0.95 20
10 0.96 0.93 0.94 142
15 1.00 0.86 0.92 7
17 1.00 0.50 0.67 14
19 1.00 0.80 0.89 5
20 0.91 0.93 0.92 54
22 0.91 0.74 0.82 70
23 0.97 0.88 0.92 32
24 0.79 0.93 0.86 228
25 0.86 0.97 0.91 99
26 1.00 0.44 0.61 16
27 1.00 0.75 0.86 8
28 1.00 0.57 0.73 7
29 1.00 0.80 0.89 10
accuracy 0.88 732
macro avg 0.96 0.77 0.84 732
weighted avg 0.89 0.88 0.87 732
random_forest_grid_search.best_params_
{'max_depth': 50, 'n_estimators': 100}
Dari sini, dapat disimpulkan bahwa model Random Forest, meskipun kedua model tersebut overfit, memiliki performa yang paling bagus pada data development. Sehingga, kita akan gunakan model tersebut untuk memprediksi kategori video lainnya.
Save Model¶
Untuk keperluan prediksi, kita harus menyimpan model yang sudah kita latih sehingga dapat digunakan oleh pengguna, baik itu melalui deployment atau riset. Kita bisa gunakan joblib untuk menyimpan model random forest yang sudah kita latih tadi.
Tapi sebelum itu, kita juga harus simpan langkah-langkah pemrosesan teks TF-IDF ke dalam model. Oleh karena itu, kita akan buat sebuah model pipeline menggunakan sklearn.pipeline.Pipeline
model = Pipeline([
("vectorizer", TfidfVectorizer(
min_df=.015,
max_df=.7,
ngram_range=(1, 1),
)),
("model", RandomForestClassifier(
max_depth=50,
n_estimators=75,
random_state=11
))
])
# training
model.fit(X_train, y_train)
pred = model.predict(X_dev)
print("Reports on train set:",
classification_report(
y_train,
model.predict(X_train)
),
sep="\n"
)
print("Reports on dev set:", classification_report(y_dev, pred), sep="\n")
Reports on train set:
precision recall f1-score support
1 1.00 0.99 0.99 81
2 1.00 0.96 0.98 80
10 1.00 1.00 1.00 566
15 1.00 1.00 1.00 26
17 0.96 0.98 0.97 54
19 1.00 0.89 0.94 19
20 1.00 1.00 1.00 216
22 1.00 0.98 0.99 279
23 1.00 0.98 0.99 126
24 0.98 1.00 0.99 913
25 1.00 1.00 1.00 395
26 1.00 0.97 0.98 65
27 1.00 1.00 1.00 34
28 1.00 1.00 1.00 28
29 1.00 1.00 1.00 42
accuracy 0.99 2924
macro avg 1.00 0.98 0.99 2924
weighted avg 0.99 0.99 0.99 2924
Reports on dev set:
precision recall f1-score support
1 1.00 0.55 0.71 20
2 1.00 0.80 0.89 20
10 0.96 0.93 0.95 142
15 1.00 0.86 0.92 7
17 1.00 0.50 0.67 14
19 1.00 0.80 0.89 5
20 0.91 0.93 0.92 54
22 0.93 0.74 0.83 70
23 0.97 0.88 0.92 32
24 0.78 0.93 0.85 228
25 0.84 0.97 0.90 99
26 0.88 0.44 0.58 16
27 1.00 0.75 0.86 8
28 1.00 0.57 0.73 7
29 1.00 0.80 0.89 10
accuracy 0.87 732
macro avg 0.95 0.76 0.83 732
weighted avg 0.89 0.87 0.87 732
joblib.dump(model, "model/model.joblib")
['model/model.joblib']
Untuk mengecek apakah model benar-benar sudah tersimpan, kita akan load modelnya dan gunakan untuk memprediksi data development yang harusnya memiliki laporan klasifikasi yang sama pada laporan sebelumnya.
model = joblib.load("model/model.joblib")
print(model.get_params())
{'memory': None, 'steps': [('vectorizer', TfidfVectorizer(max_df=0.7, min_df=0.015)), ('model', RandomForestClassifier(max_depth=50, n_estimators=75, random_state=11))], 'verbose': False, 'vectorizer': TfidfVectorizer(max_df=0.7, min_df=0.015), 'model': RandomForestClassifier(max_depth=50, n_estimators=75, random_state=11), 'vectorizer__analyzer': 'word', 'vectorizer__binary': False, 'vectorizer__decode_error': 'strict', 'vectorizer__dtype': <class 'numpy.float64'>, 'vectorizer__encoding': 'utf-8', 'vectorizer__input': 'content', 'vectorizer__lowercase': True, 'vectorizer__max_df': 0.7, 'vectorizer__max_features': None, 'vectorizer__min_df': 0.015, 'vectorizer__ngram_range': (1, 1), 'vectorizer__norm': 'l2', 'vectorizer__preprocessor': None, 'vectorizer__smooth_idf': True, 'vectorizer__stop_words': None, 'vectorizer__strip_accents': None, 'vectorizer__sublinear_tf': False, 'vectorizer__token_pattern': '(?u)\\b\\w\\w+\\b', 'vectorizer__tokenizer': None, 'vectorizer__use_idf': True, 'vectorizer__vocabulary': None, 'model__bootstrap': True, 'model__ccp_alpha': 0.0, 'model__class_weight': None, 'model__criterion': 'gini', 'model__max_depth': 50, 'model__max_features': 'auto', 'model__max_leaf_nodes': None, 'model__max_samples': None, 'model__min_impurity_decrease': 0.0, 'model__min_samples_leaf': 1, 'model__min_samples_split': 2, 'model__min_weight_fraction_leaf': 0.0, 'model__n_estimators': 75, 'model__n_jobs': None, 'model__oob_score': False, 'model__random_state': 11, 'model__verbose': 0, 'model__warm_start': False}
preds = model.predict(X_dev)
print(classification_report(y_dev, preds))
precision recall f1-score support
1 1.00 0.55 0.71 20
2 1.00 0.80 0.89 20
10 0.96 0.93 0.95 142
15 1.00 0.86 0.92 7
17 1.00 0.50 0.67 14
19 1.00 0.80 0.89 5
20 0.91 0.93 0.92 54
22 0.93 0.74 0.83 70
23 0.97 0.88 0.92 32
24 0.78 0.93 0.85 228
25 0.84 0.97 0.90 99
26 0.88 0.44 0.58 16
27 1.00 0.75 0.86 8
28 1.00 0.57 0.73 7
29 1.00 0.80 0.89 10
accuracy 0.87 732
macro avg 0.95 0.76 0.83 732
weighted avg 0.89 0.87 0.87 732